While we are talking about Microservices, we talked a lot about Domain-Driven design, Event-Driven Architecture, Core domain, Subdomain, Bounded context, Anti-corruption Layer, etc,
Whether you are working in a Brownfield project or a Green Field project, If your organization wants to adopt Microservices, (assuming your organization has a compelling reason for adopting Microservices as it is not a free lunch.) then you need to understand the above terms in detail to properly decomposing your Business domain logic(Business Space) and mapped it with Microservices architecture(Code Space) , so you can gain the benefits of Microservice traits.
In this article, I will try to cover the purposes of the above-mentioned terms while decomposing Microservices and try to fit them under one umbrella concept.
To understand each term from the root, it must be one or more than one article. Having said that, I will concise them in this article and give you the pointers while you are applying the Microservice decomposition strategy in your Organization.
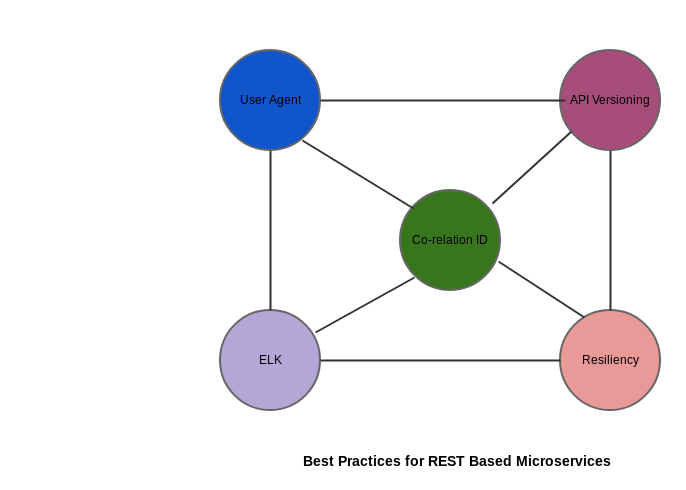
Let’s begin with the 10 Commandments of Microservice Decomposition.
1. View Your Business Domain In terms of Bounded Context and Ubiquitous Language::
Before taking any step on decomposition, the first thing first is to reduce the gap between Product owners and developers, Product owners do not understand Technical term, and the Technical team not understand the importance of a term in terms of Business and how business interpret it, It is like one Portugees talking with one American with their native language no one understood the conversation, so to bridge the gap we need to take below steps,
gather in front of a Drawing board start a discussion with Product owners what is the objective of the business, what are the actors in a particular feature, what are the terms they used while defining the feature, on every step ask more questions until you figure out what are the conflicting terms, like in Order Context Customer is different than Infrastructure Support context Customer.
Once you understand the conflicting terms and clubbed the related feature, draw a context so that in each context every domain entity name is clear.
Define a Ubiquitous language for each context. So the Business team and tech team in sync and using a common language when they communicate.
Start with a Coarse-grained Bounded context, later If has a compelling reason to divide then divide the bounded context, I would recommend not do that if there is a Business reason.
2. Identify the Core Domain and apply Innovative Idea::
The core domain is such domain, which brings the revenue to your Business, Say for Online shopping Shopping cart module is the core domain which gives the platform to Buy and Sell (B2C) opportunity to Business and consumers, understand your core module is and think about how you can improve that module which your competitor does not have, any automation, innovations will add advantage and boost your revenue, so pay attention, do R&D invest money on core domain to stay ahead of the competition.
3. Do Cost Optimization on Generic Domains::
Generic Domains are such domain which is common in every business in that niche, and already different Third-party already provides the solution and commercialize in the market, Like you Notification module, or Ad Campaign module for your business, it is the best strategy, not to spend money on In house project to create this module and reinvent the wheel unless you have some compelling reason, preferably adopt the Third-party solution for the cheap price.
4. Think on Support Domains::
Core domain needs the Support domains help, to enrich itself and in some cases, Support domain can lead the revenue and can be possible core domains in future. So it is important to think and take decisions to invest in the support domain so that it can generate revenue. Like in a shopping cart domain Inventory Management is Support domain but it is important to invest money to expand inventory locations to cut down the shipping cost, and also invest in algorithms, which can identify the nearest Inventory location for a Customer order to reduce shipping cost.
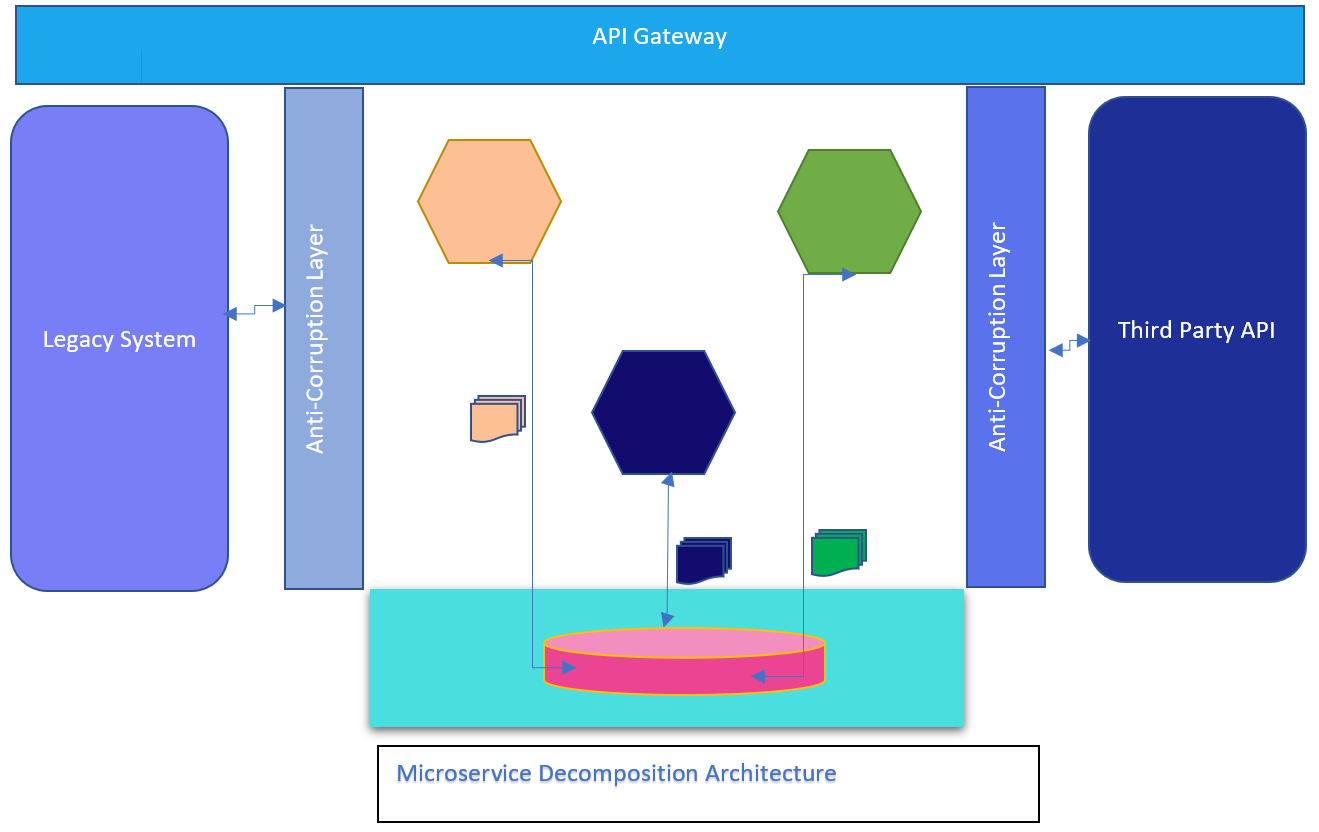
5. Introduce Anti Corruption Layer::
Anticorruption Layer is an integral part of Microservice design it protects Microservices from outerworld malformation, In a real-time Legacy project always you will encounter with such old system which builds on Mainframe or any other language, while you are doing decommission they are the important source of Microservice input data and live side by side with Microservices architecture you can not decompose that system for various reasons.
So it is a good idea to create a facade between Legacy and microservice communication, rather than directly consume data from legacy and create coupling on Microservice and Legacy architecture.
Also think on the Generic domain as they are adopting third party library so rather than directly consume/publish the data according to their contract introduce an anti-corruption layer which insulated the Microservices from outer world contract API, The Port and Hub pattern, so rather than driven by their contract we create our contract and ACL(Anti-corruption layer act as a translator between Microservice and third party contact. It helps you to adopt any third-party library in the future.
6. Identify the Data Communication patterns::
Once you decompose the microservices based on the features, and your core services encapsulated their own database/persistence layer,(database per service), the next important things to understand, to complete a feature, how your UI views/components will communicate with each other, is it a sequential flow? At a one-shot your user needs to complete the whole feature, or it can be asynchronous where the user can do a partial functionality and create an intermediate state, another system takes action on the intermediate state and calls back or notify the user to resume the action.
7. Introducing Event-Driven Architecture (EDA):
In a real-time application, your business cases having complex workflows and many branches on the workflows based on the state of the data, based on the state change, workflow took a different strategy, so if you think to expose all by Rest API, you will see that it creates a chatty network not only that each microservices coupled with others and create a spaghetti code and distributed ball of muds.
So somehow we need a clean architecture where each microservices can operate independently without creating coupling, here Event-driven architectures play a vital role, each event is wrapping a change of a state, and the Microservices are followed pub/sub model so one microservice produces it state change and wrap the necessary data in a form of event other Microservices listens to that events and can take the strategy based on the data wrapped in the event. As Events are immutable it also holds the history of an entity or aggregator so if you are adopting an event store and event storming you can generate any statistics and report from the events.
8. Make API contract Clean and concise :
In Microservices you need to publish API so it will act as a contract, so while you are publishing API make sure your api does not publish internal state, think about the encapsulation, and think about the network call, so publish API is such a way that other services can get enough information to carry on their flow, they should not come back multiple times for getting derivative information, also think about the events which events, which you should publish and which must remain inside, maybe you can publish one coarse-grained event rather than publish small internal events.
Example: say internally you have Address Change Event, Personal info change event rather than publish both in API contract, publish a Coarse-grained event called CustomerUpdateEvent.
9. Merge Related Microservices to a Bigger Service::
After decomposing if you can experience, few microservices always changing together when a feature needs to be added or updated, then you know, you decomposed it in the wrong way, they must not be segregated to a small service they are part of the same logical unit so it is wise to merge them a single service, it will reduce unnecessary coupling and network call.
10. Introduce Supporting tool for Seamless development::
Microservices is not free lunch, If you adopt Microservices first thing first be ready to expense on the supporting software as Microservice is distributed we adopt it for scaling resiliency and high availability and reduce Time to Market, it is distributed and works over the network so failure is inevitable and you need to catch the failure at the earliest without spending on infrastructure it is not possible.
If you spend well, then only Microservice allows you to buy out different options and help your organization to grow further.
So spend on CI/CD pipeline, adopt cloud infrastructure, use Tracing tool, use Log aggregator to search logs, use chaos tools for checking how you are prepared for failure, etc.
Conclusion ::
The above points are necessary while you are decomposing Microservices, I will write an article on each topic on how they play a pivotal role in adopting Microservices architecture.
Also, like to hear from you more on the challenges you faced while decomposing to Microservices.